




[Le Fonds Informatique Pionnière en Belgique de la FRB possède deux tambours magnétiques Univac qui sont actuellement exposés au Computer Museum NAM-IP.]
Ce tambour (photo 1), en anglais «drum memory», provient d’un USSC90, ou UNIVAC Solid State Computer qui fut mis sur le marché en 1958. L’USSC était la version commerciale de l’UNIVAC Cambridge Computer qui fut construit par l’armée américaine en 1956. Le chiffre 90 se réfère à l’utilisation de cartes de 90 colonnes telles qu’utilisées chez Remington (Powers). Il y eut également une version avec cartes de 80 colonnes, le USSC80.
Ce tambour fut l’ancêtre des disques durs et on le retrouve dans presque tous les ordinateurs de cette époque, parfois utilisé en parallèle avec des disques durs. Mais ce n’était pas un support permanent de données comme les disques durs.
Dans l’USSC90 le tambour était la seule mémoire disponible et se comportait donc comme les mémoires des ordinateurs plus récents. On chargeait sur le tambour aussi bien les programmes que les données. Le processeur allait alors chercher ses informations sur le tambour et les traitait. Il y avait aussi sur le tambour une piste pour l’horloge du processeur.
Le tambour tournait à 17.670 tours à la minute. Cette vitesse était nécessaire pour faire correspondre l’horloge avec la fréquence de 707 kHz. En raison de cette très grande vitesse, l’engin devait être refroidi et, pour que la stabilité de l’air soit réduite au minimum, le tambour était enfermé hermétiquement dans un container rempli d’hélium. Une technologie qu’on utilise encore parfois pour les disques de grande capacité aujourd’hui !
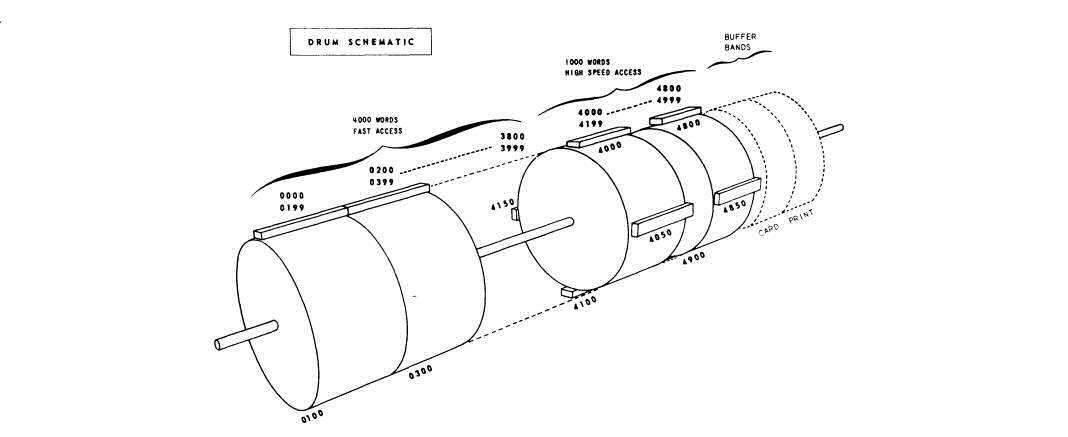
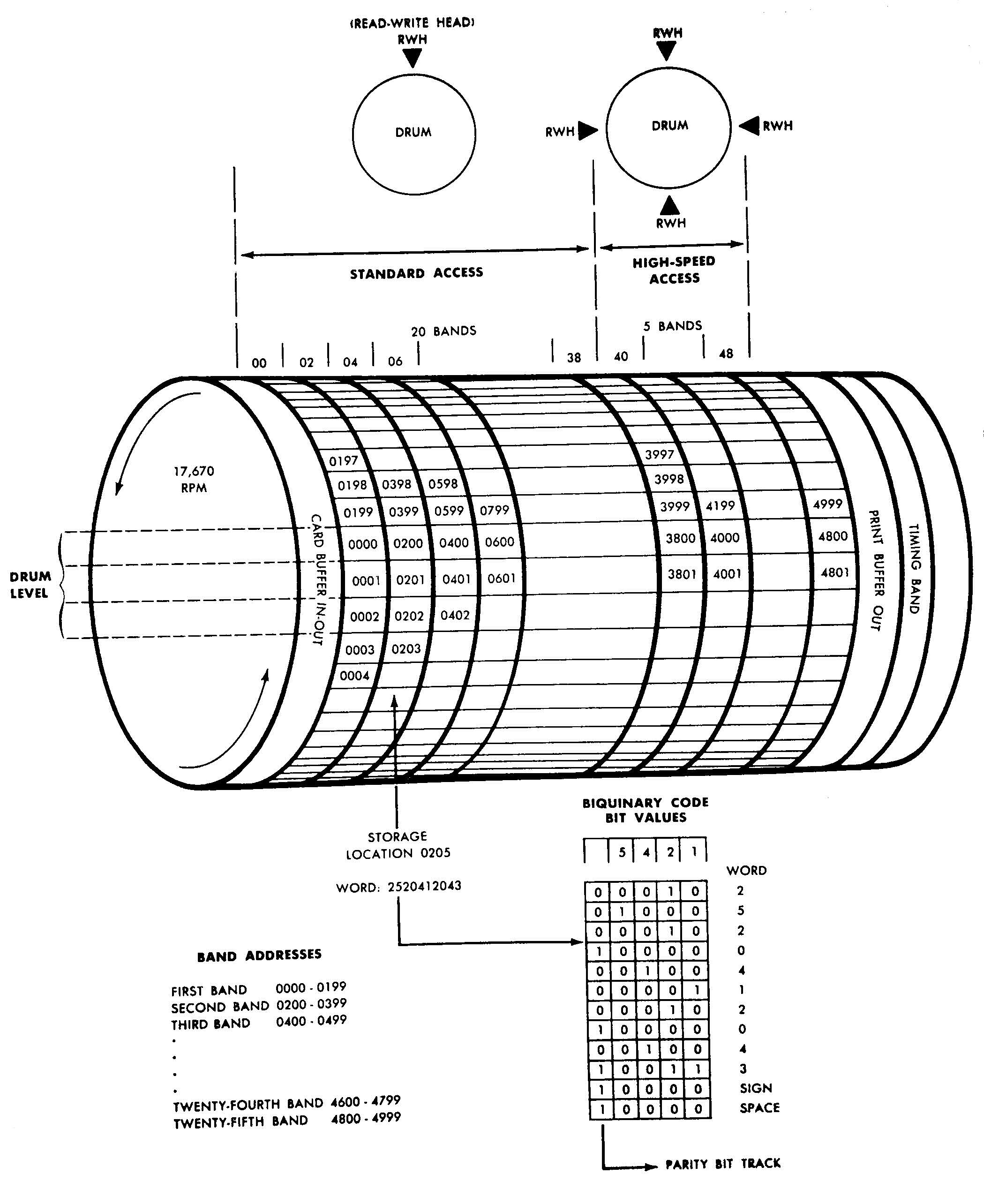
La capacité de stockage du tambour était seulement de 60 à 70 kilobytes. Il y avait place pour 5.000 mots de 12 caractères (10 caractères de données, un signe, et un SBW ou «space between words»). Le tambour était divisé en 25 champs qui contenaient chacun 200 mots. Chaque caractère était codé en code bi-quinaire. C’est-à-dire: un code de 4 bits mais avec une valeur de 5 et non de 8 pour le bit le plus élevé.
| biquinaire | binaire | |
| valeur | position du bit | position du bit |
| 4 3 2 1 | 4 3 2 1 | |
| 0 | 0 0 0 0 | 0 0 0 0 |
| 1 | 0 0 0 1 | 0 0 0 1 |
| 2 | 0 0 1 0 | 0 0 1 0 |
| 3 | 0 0 1 1 | 0 0 1 1 |
| 4 | 0 1 0 0 | 0 1 0 0 |
| 5 | 1 0 0 0 | 0 1 0 1 |
| 6 | 1 0 0 1 | 0 1 1 0 |
| 7 | 1 0 1 0 | 0 1 1 1 |
| 8 | 1 0 1 1 | 1 0 0 0 |
| 9 | 1 1 0 0 | 1 0 0 1 |
| valeur décimale | 5 4 2 1 | 8 4 2 1 |
Les 25 champs étaient divisés en une zone de «fast access» de 4.000 mots et une zone de «high speed access» de 1.000 mots. La zone «fast access» était desservie par une tête logique de lecture et d’écriture. Sa rapidité moyenne était de 1,7 millisecondes. Dans cette zone étaient traités les programmes et tabulations. La zone «high speed access» avait quatre têtes logiques de lecture et d’écriture placées à 90° tout autour du cylindre. Grâce à cela la rapidité moyenne était de seulement 0,425 millisecondes. Les données chargées étaient transférées vers là à partir de la zone du buffer pour être ensuite traitées. Les résultats étaient renvoyés vers la zone du buffer pour être transmis aux périphériques. La catégorie des instructions de transfert servait à cette opération. Des résultats intermédiaires des travaux pouvaient aussi parfois être traités dans cette zone. La vitesse de transmission était de 707.000 unités (digits) par seconde.
Les têtes d’écriture et de lecture (photo 2) étaient livrées en séries de cinq pièces. Cela explique le nombre élevé de têtes de lecture que l’on peut voir tout autour du tambour. Les unités (digits) étaient lues en série: les 5 unités de données étaient lues en parallèle.
Au travers de l’ouverture laissée libre par la tête de lecture, on voit le cylindre (photo 3) sur lequel étaient fixées les données.
À côté de l’espace pour les données (tant de programmes que de données à traiter), il y avait une zone de buffer pour chaque type de périphérique. Cette zone comprenait 280 mots et servait, comme son nom l’indique, à combler la différence de vitesse entre l’unité centrale et les machines d’entrée et de sortie de données. Durant le temps nécessaire à imprimer une ligne sur l’imprimante, le tambour pouvait faire environ 30 tours et pouvait donc traiter toute une série de données. Les données introduites à partir du lecteur de cartes vers la zone de buffer étaient transférées par le processeur vers la «high speed» zone. La sortie de données traitées étaient réinscrites par le processeur sur la zone buffer et de là vers la machine à perforer ou vers l’imprimante.
Une instruction pour cette machine comprenait, à côté du code ‘instruction spécifique («par exemple: add, substract., etc), l’adresse sur le tambour des données qui devaient être traitées et, au bout, l’adresse de l’instruction suivante à traiter sur le tambour. Le calcul de cette adresse était toute une affaire. Quand une instruction avait été traitée, le tambour avait déjà fait une série de tours. La place de la prochaine instruction n’était donc pas l’adresse qui suivait sur le tambour. Pour être le plus efficace possible, le programmeur devait en tenir compte.
Sur le site du Smithsonian Institute on trouve une règle à calcul circulaire la «Minimum Latency Calculator slide rule» (photo 4) qui servait à cet usage.
Cette représentation (photo 5) montre en détail comment le code 25 20141 0243 est introduit à la position 0205. On voit aussi les tranches de buffer et les « timing band ». La terminologie est un peu différente ici: on parle de « standard access » et de « high-speed access ». La « timing band » comportait également une horloge comme information d’adressage pour la lecture de données dans les zones « fast access » des « high speed access ». Le signal d’horloge desservait tous les circuits logiques dans le processeur grâce à un amplificateur de 1 kilowatt de puissance.
Sources: (Liens valables au moment de la publication de cet article)
• https://web.archive.org/web/20160304164142/
• https://wiki.cc.gatech.edu/folklore/index.php/The_UNIVAC_Solid_State_Computer
Collection
Ward Desmet